 What is Apache NiFi
What is Apache NiFi
Apache NiFi is a powerful web-based tool for scheduled ETLs and many other types of data-related tasks.
It implements an innovative approach to deal with data loading and manipulation.
Its logic is based on an abstraction called “FlowFile” generated and directed through “processors” whose role is to do the practical operations such as calling services, retrieving, modifying, and storing data.
To show some of the capabilities and limits of this framework, I will explain my approach to merging two CSV files about Italian Covid-19 cases and vaccines.
Case Study: Italian Covid-19 cases and vaccines
This real case study was created to set up the automatic data loading procedure and populate the Bstreams Data Hub, a data repository where we collect various data of topical interest.
Here there are some public-free datasets that standard users can use to create their BStreams; moreover, enterprise users can also access their private datasets. One of the services we offer is to prepare a bunch of data sets on behalf of our customers, collecting, analyzing, and saving the data directly on the Data Hub.
Therefore, business users who have private and secure access to the Data Hub can analyze their datasets using BStreams or download and use them with Excel or other applications. Furthermore, most of these datasets are automatically updated, so every related BStreams, even those published, will constantly be refreshed with new data.
Merging two CSV files with Apache NiFi
The data is divided by Italian regions in both files. The key used is the concatenation of the region code and the date on which the data was collected. In this practical example, I will show the four critical points on merging two CSV files using the Apache NiFi tool.

1. Data retrieval from web sources
Firstly, I have used the GenerateFlowFile processor to create the flow that is then split and directed the two InvokeHTTP processors collecting the raw CSV files from public GitHub repositories of the Italian government and the Civil Protection Department.

2. CSV file transformation and preparation for the merging in NiFi
Secondly, the next step was to prepare the key field for the join, meaning unifying the date format and region code between the two files and then appending them in a single field.
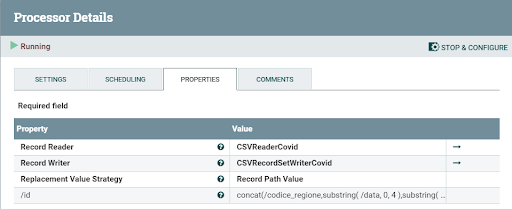
For what concerns the covid cases, the date field also had the timestamp of the recording; thus, it has been necessary to use the ReplaceText processor to eliminate the timestamp part and the UpdateRecord processor to concatenate it to the region code.
The ReplaceText processor uses the regex to recognize the string that must be deleted using a line-by-line evaluation mode, while the UpdateRecord processor uses two different Controller Services: a CSVReader to read the file and a CSVRecordSetWriter to write the new CSV.
Moreover, the writer contains the JSON schema definition in which there is a new field containing the join key, as illustrated in the image below.
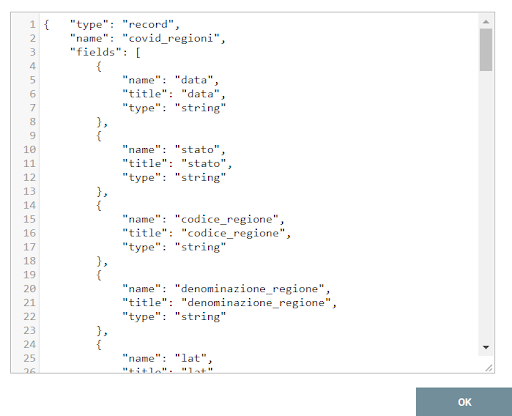
In this case, the new field’s name is “id”, and the Concat function is used to append the date numbers to the region code.
3. The merging of the two FlowFiles before the join
Then, after the join field is ready, the flow must pass through a UpdateAttribute processor that will add a new attribute used later to discriminate between the two flows in the final join.
The covid cases’ flow will have the new metric attribute set as “a” and the fragment.index as “0”, while the vaccines’ flow will have “b” as the metric attribute and “1” as the fragment.index.
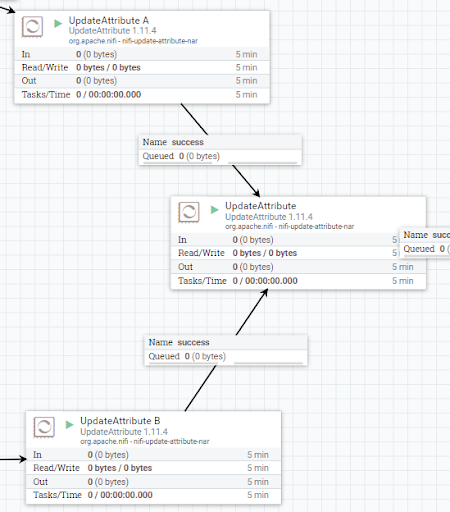
The follow-up consists of another UpdateAttribute processor that will recall a JSON schema defined in an AvroSchemaRegistry controller service. We will put all the fields of the two CSV files that we want to propagate forward together with a new field used in the next processor.
4. Joining between the two datasets through SQL query
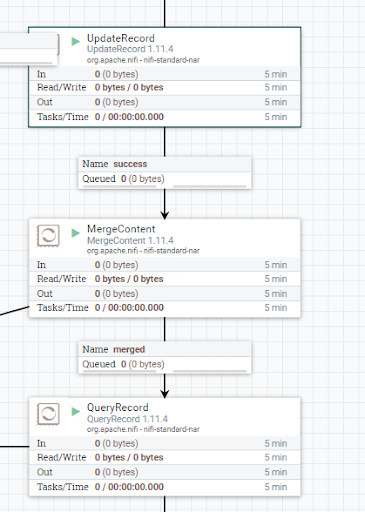
Lastly, the last step is a UpdateRecord processor used to populate the new field defined in the previous processor with the values of the metric attribute: “a” for the covid cases and “b” for the vaccines.
Then the two flows are merged, and the unified FlowFile is then passed through a QueryRecord processor that uses ANSI SQL syntax to query it.

This last processor is the one that does the join between the two parts of the merged FlowFile, and that uses an AvroReader controller service and a CSVRecordSetWriter to read the data and write the result of the query in a new CSV file. For some reason that I haven’t been able to understand, the join field must be of a numerical type and not a string type.
The processors are then scheduled to run at a specified time and thus provide updated data every day.
The new CSV file is ready to be stored on an AWS S3 bucket using the PutS3Object processor.
In this particular case, the dataset is prepared to be readily and freely available in the BStreams Data Hub. Therefore, after logging into BStreams and creating a dataset from the Datasets panel, it is possible to access the Data Hub.
Conclusion
In conclusion, Apache NiFi is a handy application that gives the user many tools to work with data. It also permits the calling and execution of external scripts that can be integrated into the workflow.
The only drawback that I have found in my experience is the fact that at the beginning, the logic behind it seemed a bit counter-intuitive, and sadly the official documentation seems to be lacking a thorough explanation or practical examples.
Sources
Covid cases dataset: https://github.com/pcm-dpc/COVID-19/blob/master/dati-regioni/dpc-covid19-ita-regioni.csv
Vaccines dataset: https://github.com/italia/covid19-opendata-vaccini/blob/master/dati/somministrazioni-vaccini-summary-latest.csv